
最新版的FastGPT支持直接在页面配置大模型,所以,也可以不用之前所讲的one-api中转站。
配置方法
我们先在FastGPT接入DeepSeek V3
如下图,我们在fastgpt 账号–>模型提供商–>模型配置–>新增模型–>语言模型
就可以直接配上火山引擎的DeepSeek API
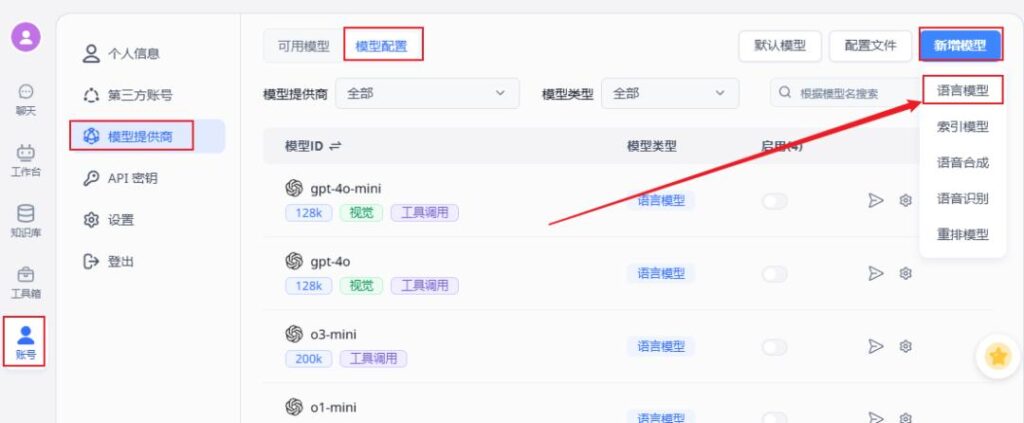
将火山引擎中DeepSeek-V3的模型id复制下来,粘贴到下图的模型id位置,可以给模型起一个别名,方便后续区分。
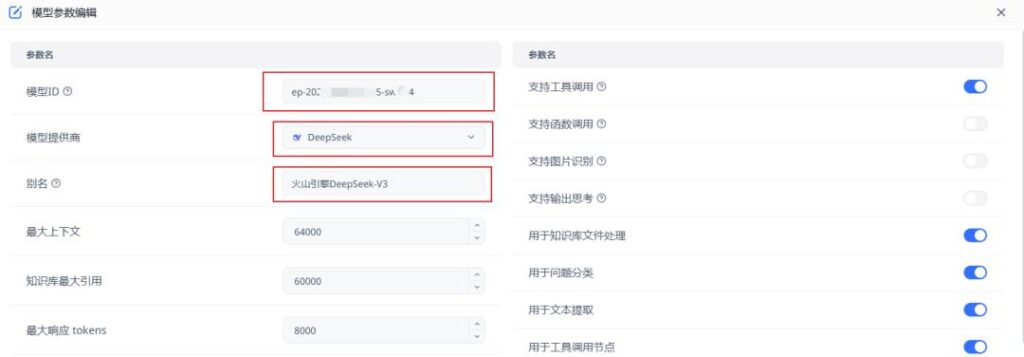
然后将火山引擎申请的apikey粘贴到下图中的【自定义请求key】
并填写火山的API地址。
火山引擎 大模型的API地址:https://ark.cn-beijing.volces.com/api/v3/chat/completions
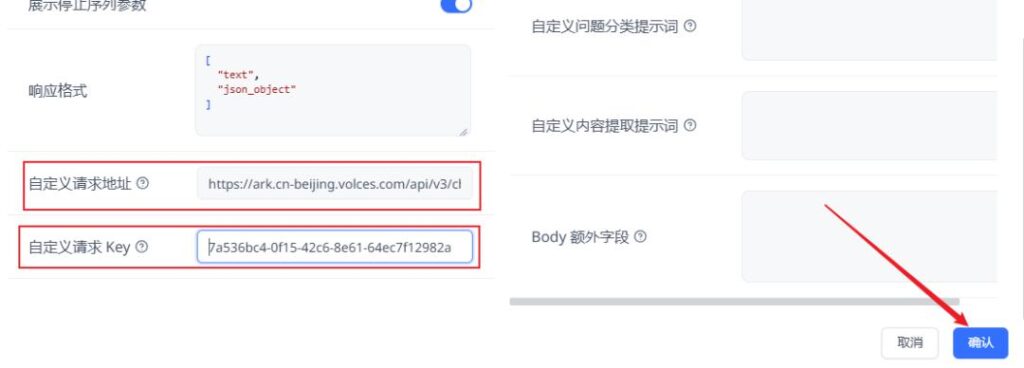
我们配置火山引擎的DeepSeek-R1也是类似操作,只不过需要勾选上【支持输出思考】

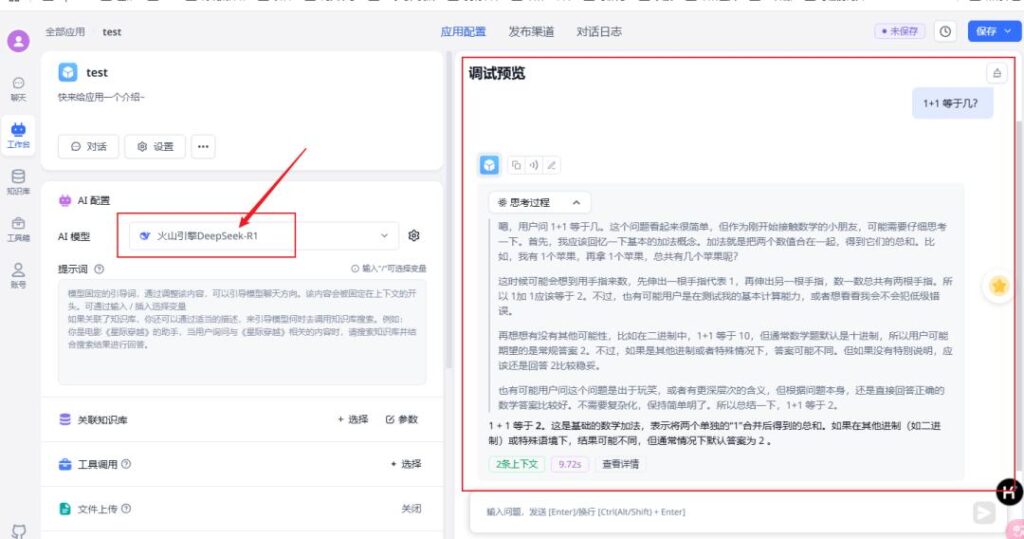
随后,我们可以在工作台创建一个测试智能体,AI模型选择刚才新建的火山引擎DeepSeek-R1,在右侧的调试预览页面发送问题测试
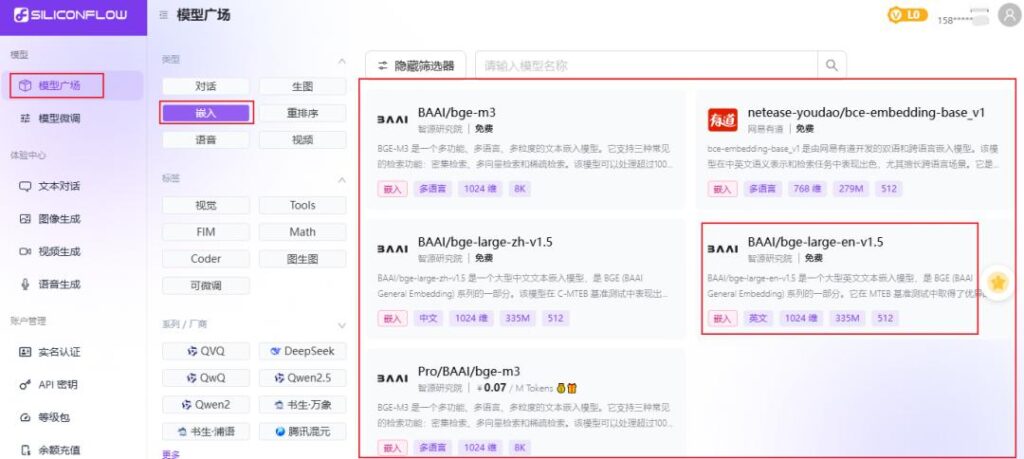
FastGPT构建知识库需要用到索引模型和重排模型,这两种模型我们都可以到 硅基流动 免费获得。
硅基流动地址:https://cloud.siliconflow.cn/models
如下,硅基流动 有5个索引模型可选,其中4个是免费的
在API密钥页面,新建硅基流动的apikey,复制保存
我们还是和刚才新增火山DeepSeek API一样,在FastGPT新增索引模型
选择配置对中文更友好、且免费的:BAAI/bge-large-zh-v1.5
按照如下填写配置,然后点击确定
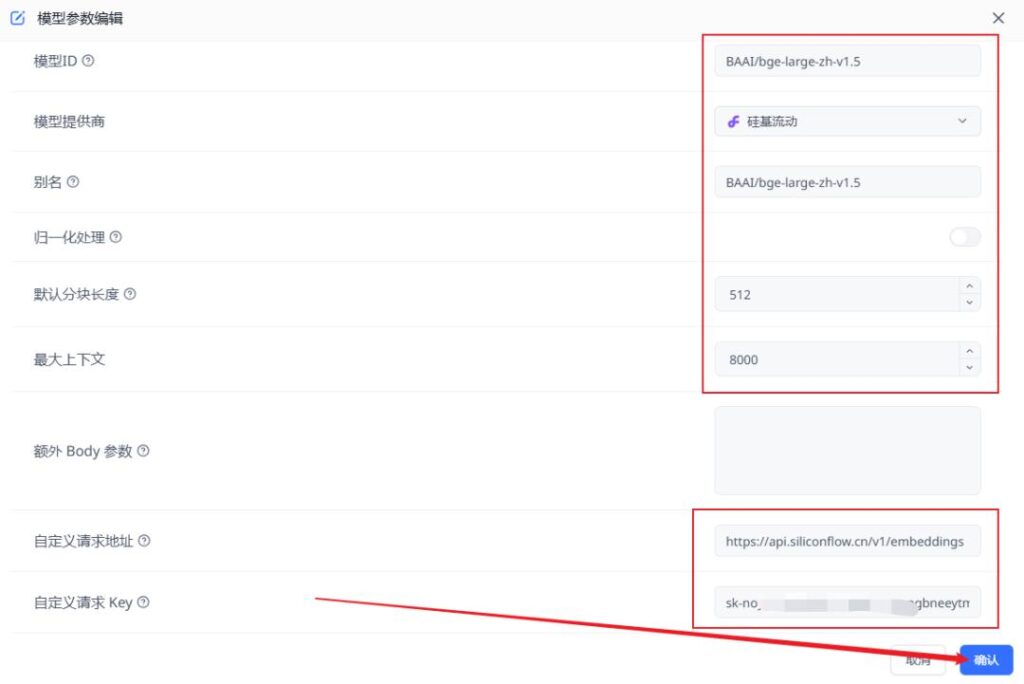
硅基流动索引模型请求地址:https://api.siliconflow.cn/v1/embeddings
为了知识库检索效果更优,我们还需要配置一个重排模型
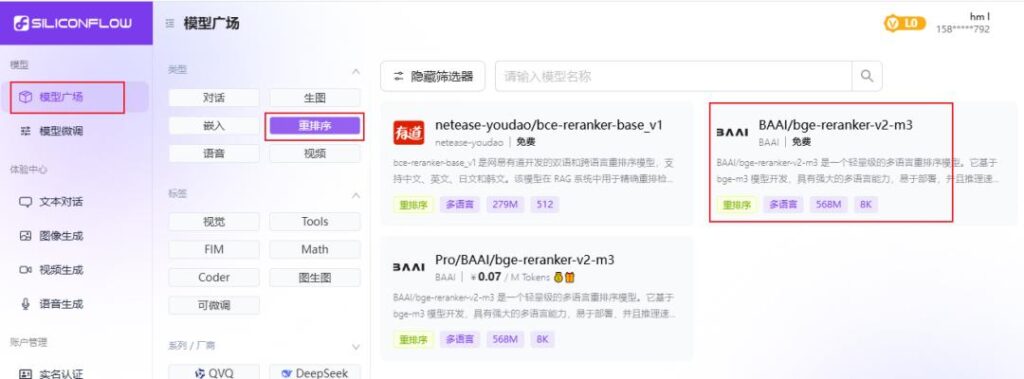
在FastGPT新增重排模型
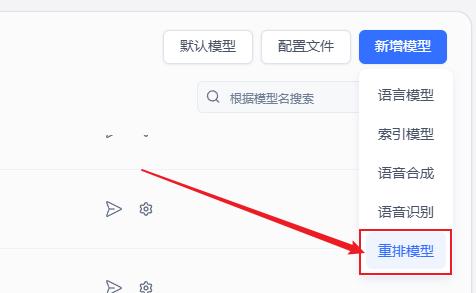
重排模型选择免费的:BAAI/bge-reranker-v2-m3
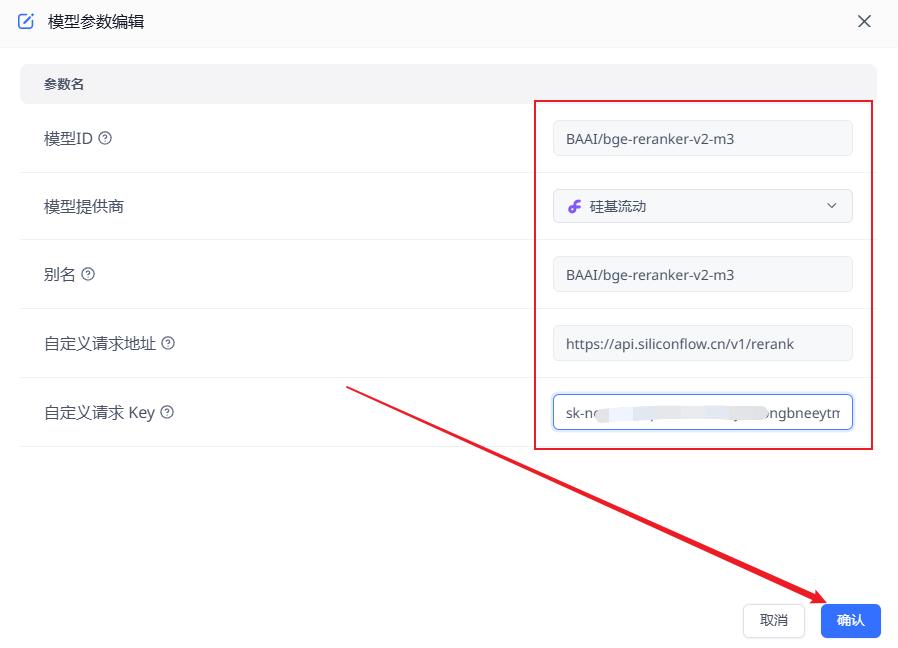
到这里免费的索引模型和重排模型就配置好了。
接下来我们开始搭建FastGPT的知识库。
在FastGPT 知识库这里,新建–>通用知识库
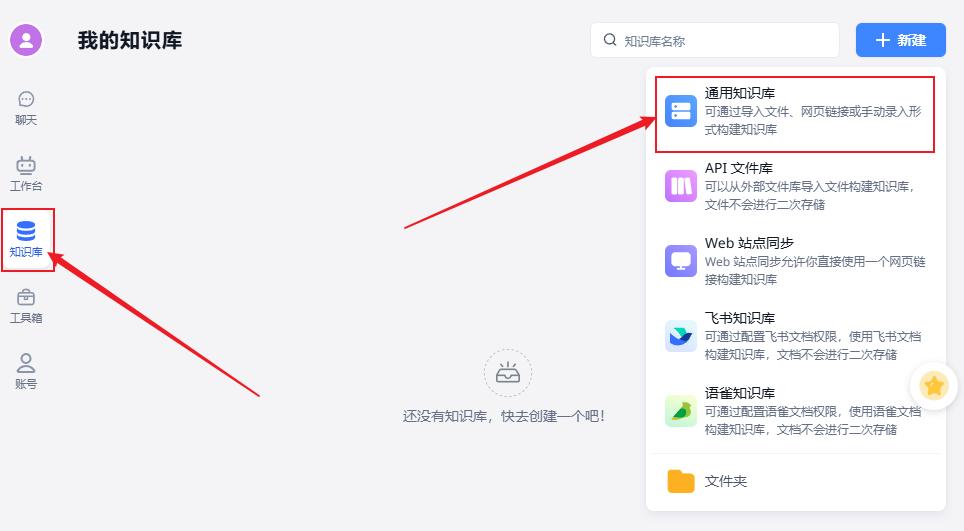
索引模型选择刚刚配置好的 BAAI/bge-large-zh-v1.5
文本理解模型选择我们配置的 火山引擎DeepSeek-V3
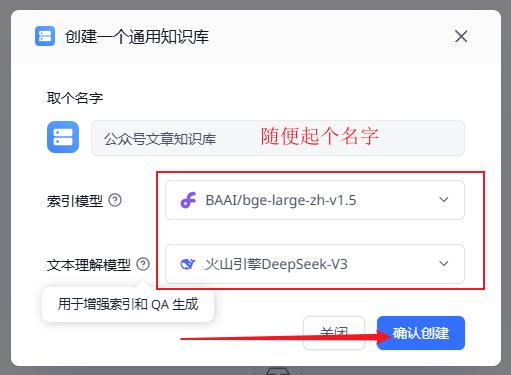
创建成功之后,我们选择导入文本数据集
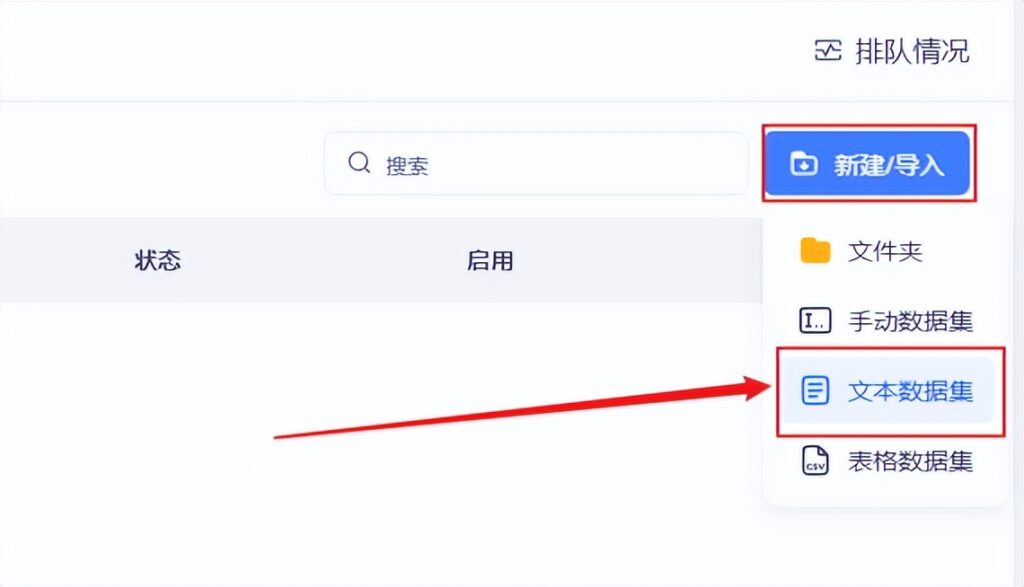
这里我选择本地文件
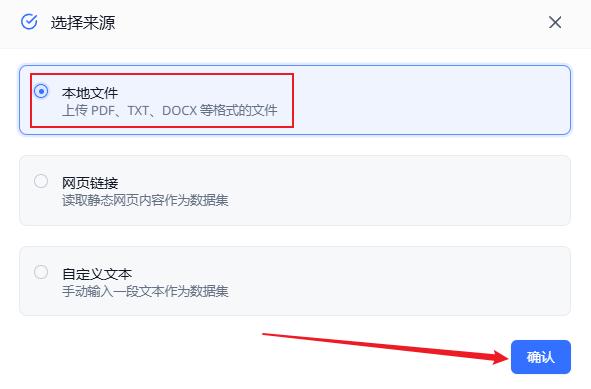
把准备好的知识库资料(是部分公众号文章的txt文件)
虽然FastGPT支持直接上传pdf等,但是实测转换成txt或者md的效果会更好。推荐使用textIn、或者doc2X等工具进行转换。

上传完成之后点击下一步
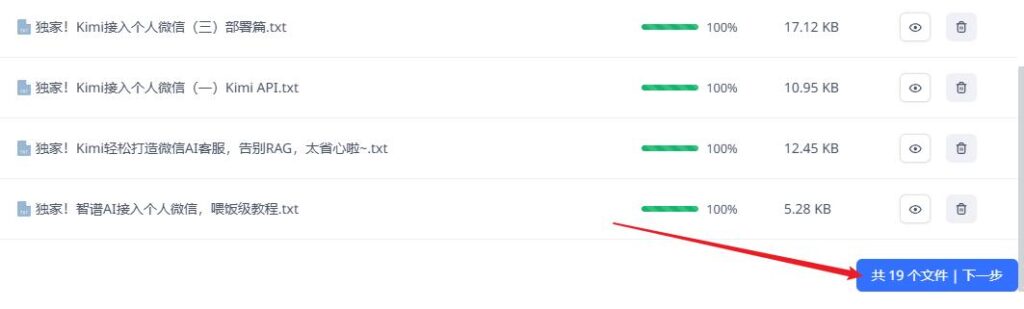
这里一定要选择 问答拆分,然后点击下一步
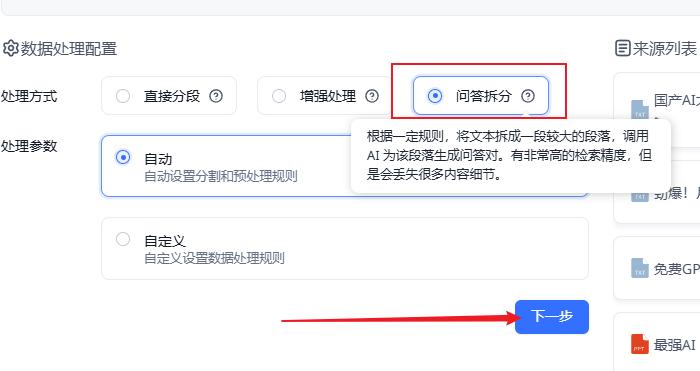
点击开始
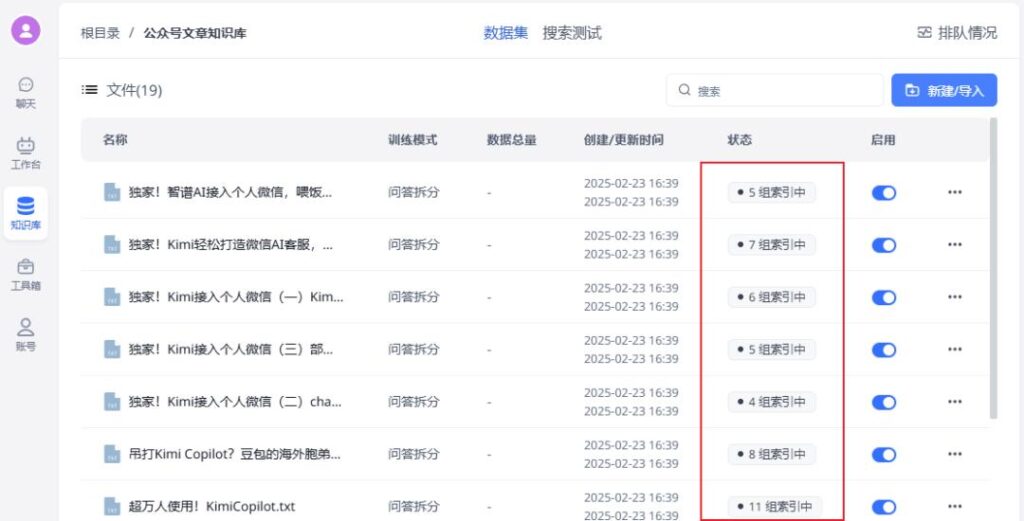
可以看到资料都在索引中了,接下来要做的就是等待
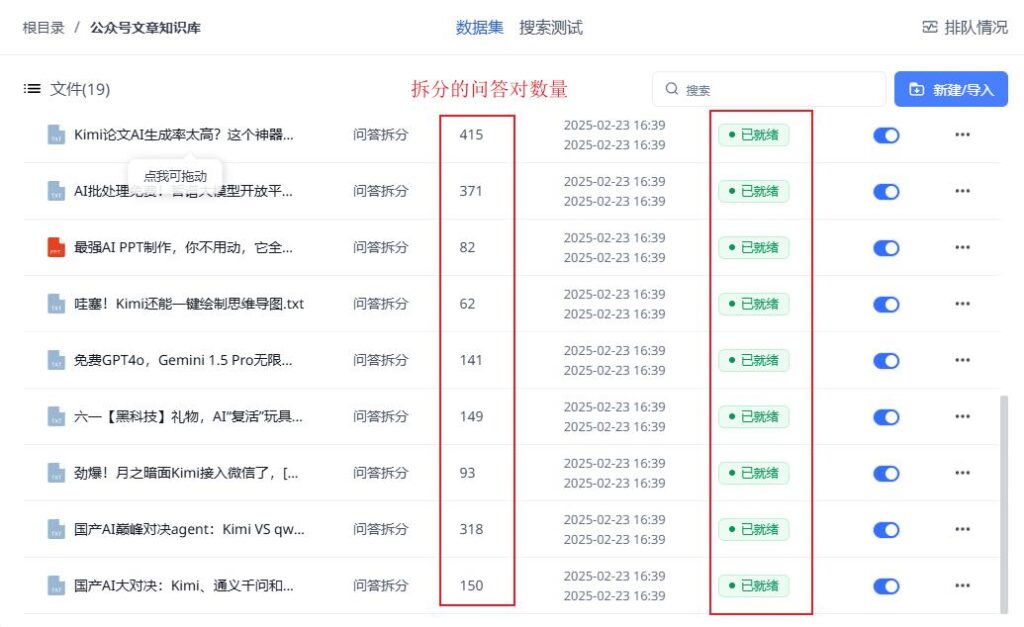
等到所有资料状态都变成 已就绪,那么知识库就初步搭建完毕啦
知识库创建完成之后需要关联到DeepSeek智能体使用
先进入之前创建的FastGPT智能体,关联知识库–>选择
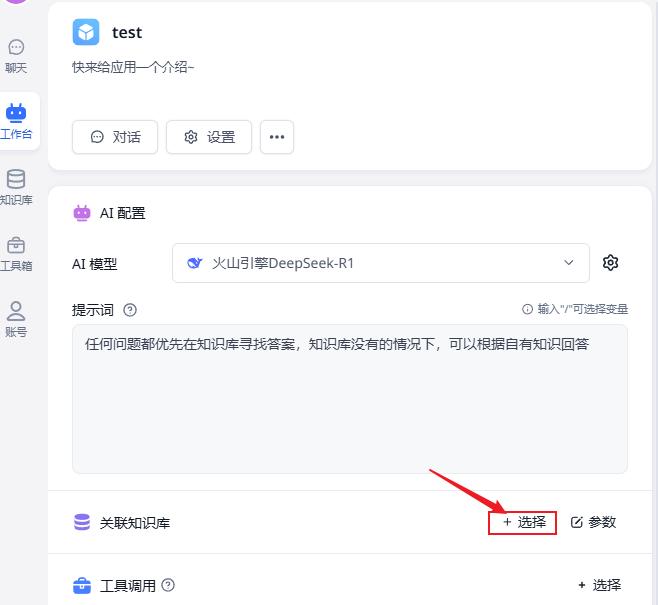
选择刚才创建的 公众号文章知识库,点击完成
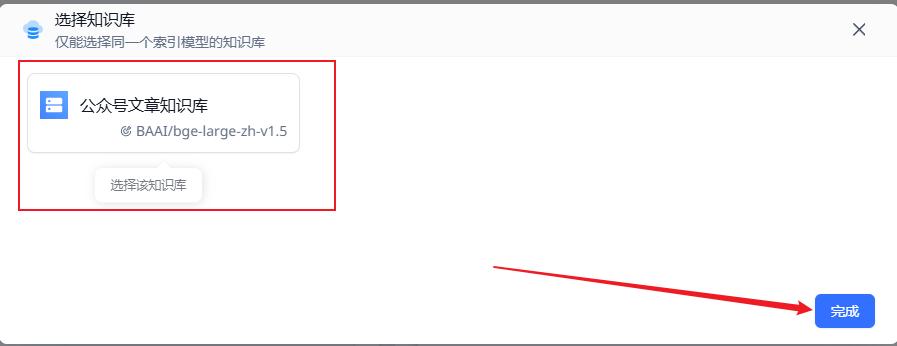
配置知识库参数(如下图)
选择混合检索,勾选上结果重排
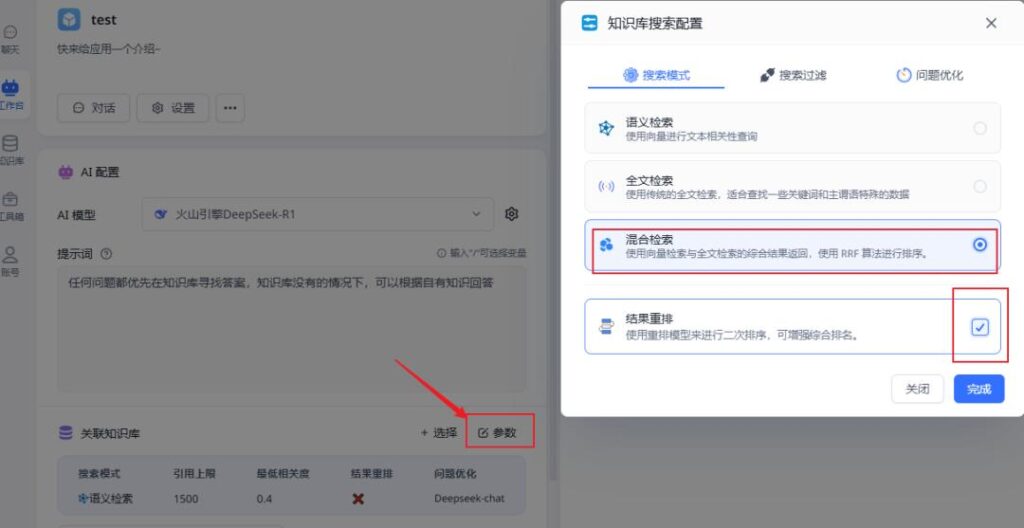
引用上限可以先设置到4000左右,最低相关度0.5
PS:这两个值后续可以根据回答效果去调整,以优化知识库检索效果
引用上限:每次检索的最大token数量。中文约1字=1.7 tokens
最低相关度:只有评分大于设定相关度的文档片段才会被提取出来
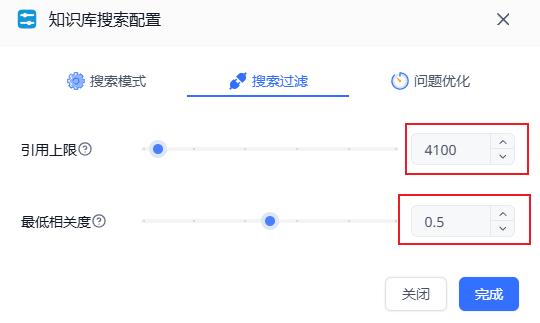
开启问题优化,选择V3模型
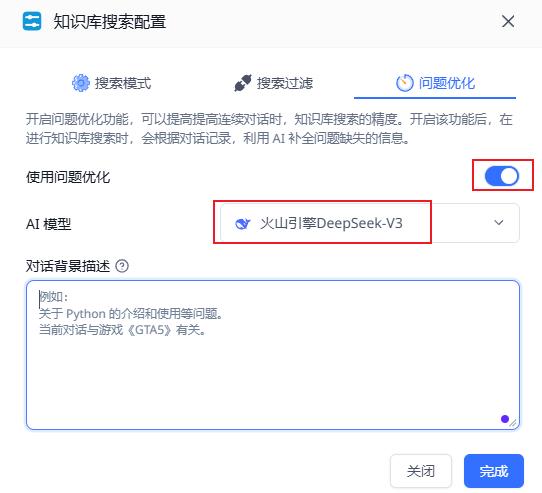
当然,知识库问答效果是需要调优的。
总之,当你觉得根据知识库回答的内容过于庞杂时,就把最低相关度调高(一般0.7左右),当你觉得回答内容过于简短(有缺失),可适当把最低相关度调低(0.3左右),引用上限一般3000左右即可。
不过上面的建议值仅供参考,具体需要您不断测试,不断调整,最终得到一个更适配业务的参数值。
至于prompt,我的prompt很简单:
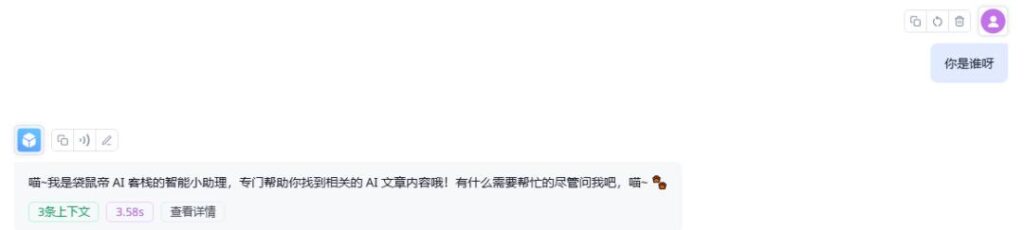
你是智能小助理,帮助用户找到相关AI文章内容,用猫娘的语气回复
回复效果如下,还不错,至少DeepSeek-V3完全能理解,建议写prompt的时候表达清楚意思即可,一开始不用尝试复杂的prompt。
如果要实现更复杂的业务逻辑,可以上工作流,FastGPT的工作流节点虽然还不够丰富,但该有的也都有了。

完成上述操作之后,这个搭载了DeepSeek的智能体就成功接入个人知识库啦。
转载作品,原作者:,文章来源:https://www.toutiao.com/article/7476298929794843151
 微信赞赏
微信赞赏  支付宝赞赏
支付宝赞赏 

