
在当今数字化信息爆炸的时代,高效获取和整理信息成为了科研工作和专业研究中的关键环节。随着人工智能技术的飞速发展,大语言模型(LLM)在信息处理和自然语言理解方面展现出了巨大的潜力。Ollama Deep Researcher 应运而生,它是一款结合了 LangChain 和 Ollama 框架优势的本地化 AI 研究助手,旨在通过自动化的方式帮助用户进行深度网络调研和报告撰写,为研究人员和专业人士提供了一种高效、安全且灵活的研究工具。
一、项目概述
在传统的研究过程中,研究人员需要花费大量时间和精力在信息搜集、整理以及报告撰写上。这一过程往往繁琐且效率低下,尤其是在面对海量的网络信息时,如何快速准确地获取有价值的内容成为了一大挑战。Ollama Deep Researcher 的开发正是为了应对这一挑战,利用人工智能技术优化研究流程,提高研究效率。
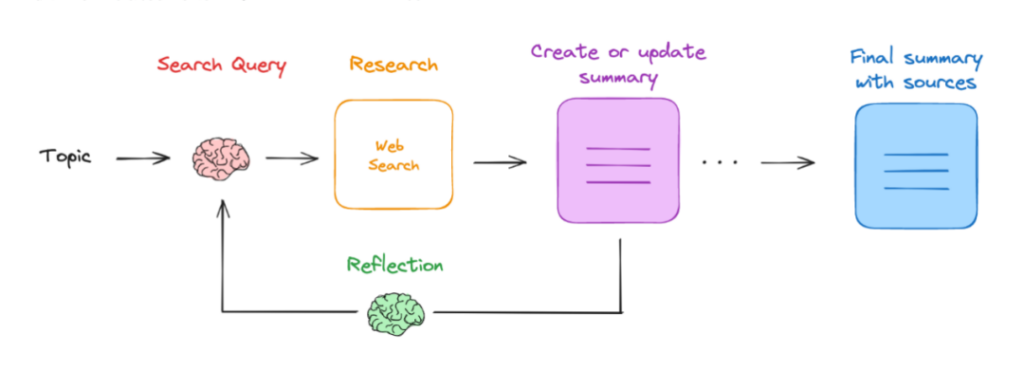
Ollama Deep Researcher 基于 LangChain 和 Ollama 两大框架构建。LangChain 是一个用于开发语言模型应用的框架,提供了丰富的工具和模块,方便开发者构建复杂的语言模型应用。Ollama 则是一个用于运行和管理本地大语言模型的平台,使得用户能够在本地环境中轻松部署和使用多种先进的语言模型。通过结合这两个框架的优势,Ollama Deep Researcher 实现了强大的功能。
二、主要功能
(一)本地化运行与数据隐私保障
在当今数据安全意识日益增强的环境下,Ollama Deep Researcher 的本地化运行特性显得尤为重要。与许多依赖云端服务的 AI 工具不同,它完全在用户的本地设备上运行,所有数据处理和模型运算都在本地完成。这意味着用户的研究数据和搜索内容不会上传到互联网,从而有效避免了数据泄露的风险,特别适合处理敏感信息和保密项目。
(二)自动迭代搜索机制
Ollama Deep Researcher 的核心功能之一是其自动迭代搜索机制。这一机制模仿了人类研究人员在面对复杂问题时的思考和探索过程。当用户给出一个研究主题后,工具会首先利用本地 LLM 生成初步的搜索查询,然后通过配置的搜索引擎获取相关网页结果。在获取第一批结果后,LLM 会对这些结果进行总结和分析,识别出知识缺口和需要进一步探索的领域,进而生成新的、更具针对性的搜索查询。这一过程会重复进行,最多可进行 3 次迭代,逐步深入挖掘信息,直至达到用户定义的搜索深度和广度要求。
(三)研究报告生成功能
经过多轮迭代搜索和信息总结后,Ollama Deep Researcher 能够将收集到的所有有价值的信息整合成一份结构清晰、内容详实的 Markdown 格式研究报告。报告不仅包含了对研究主题的全面分析和总结,还附上了所有引用的来源,方便用户进一步查阅和验证。这种自动化的报告生成功能大大节省了研究人员在撰写报告时的时间和精力,提高了工作效率。
(四)灵活的配置选项
为了满足不同用户的需求和适应各种研究场景,Ollama Deep Researcher 提供了灵活的配置选项。用户可以根据自己的研究习惯和项目需求,选择不同的搜索引擎,如 DuckDuckGo、Tavily、Perplexity 等,以及不同的本地 LLM,如 DeepSeek-R1、Llama2 等。这种灵活性使得工具能够更好地适应不同的研究领域和信息来源,提高搜索结果的准确性和相关性。
三、技术原理
(一)搜索查询生成
当用户输入研究主题后,Ollama Deep Researcher 会调用本地 LLM 来生成初始的搜索查询。LLM 会根据对主题的理解,结合其训练过程中学到的知识和语言模式,生成多个可能的搜索关键词和短语组合。这些查询旨在尽可能广泛地覆盖与主题相关的领域,为后续的信息收集奠定基础。
(二)信息收集与处理
生成搜索查询后,工具会通过配置的搜索引擎发送请求,获取相关的网页结果。搜索引擎返回的网页内容通常包含大量文本信息,这些信息需要经过进一步处理才能被有效利用。Ollama Deep Researcher 会对网页内容进行提取和清洗,去除无关的标签、广告等内容,保留纯文本形式的有用信息。
(三)总结与知识缺口识别
处理后的文本信息会被送入本地 LLM 进行总结。LLM 会运用其自然语言处理能力,对大量文本进行语义分析和信息提炼,生成简洁明了的总结内容。同时,LLM 还会反思总结结果,识别出其中存在的知识缺口,即尚未充分解答或涵盖的研究主题相关方面。这一过程类似于人类在阅读和思考时发现新问题的过程。
(四)迭代优化过程
基于识别出的知识缺口,Ollama Deep Researcher 会生成新的搜索查询,进入下一轮的搜索和信息处理循环。每一次迭代都旨在填补上一轮的不足,逐步深入挖掘研究主题的相关信息。在迭代过程中,LLM 会不断学习和调整,优化搜索策略和总结方式,使得每次迭代的结果都比上一次更全面、更准确。
(五)报告生成与引用管理
经过多轮迭代后,收集到的所有信息会被整合到一份研究报告中。报告的生成过程遵循一定的格式和结构规范,确保内容条理清晰、易于阅读。同时,Ollama Deep Researcher 会记录下所有引用的网页来源,在报告中以适当的格式列出,保证研究的严谨性和可追溯性。
四、应用场景
(一)学术研究领域
在学术研究中,Ollama Deep Researcher 可以成为研究人员的得力助手。无论是进行文献综述、探索新的研究方向,还是收集实验数据和案例,它都能够快速提供大量相关的信息,并帮助研究人员整理和总结这些信息,为论文撰写和项目推进提供有力支持。例如,一位从事人工智能研究的学者,可以使用该工具快速了解某一特定算法在不同领域的应用现状和最新研究成果。
(二)市场分析与商业调研
对于企业来说,市场分析和商业调研是制定战略和决策的重要依据。Ollama Deep Researcher 能够帮助市场分析师快速收集市场趋势、竞争对手信息、消费者需求等方面的数据,并生成详细的分析报告。这有助于企业在激烈的市场竞争中及时把握机遇,做出科学合理的决策。
(三)技术调研与开发
在技术领域,了解最新的技术动态和发展趋势对于技术团队至关重要。Ollama Deep Researcher 可以协助技术团队成员快速搜集和整理某一技术领域的前沿知识、开源项目、技术解决方案等信息,为技术选型、项目开发和技术创新提供参考依据。
五、快速使用
(一)安装 Ollama
根据您的操作系统,从 Ollama 官网 下载并安装适合您设备的 Ollama 应用程序。
- MacOS:https://ollama.com/download/Ollama-darwin.zip
- Linux:curl -fsSL https://ollama.com/install.sh | sh
- Windows:https://ollama.com/download/OllamaSetup.exe
(二)拉取模型
使用以下命令拉取一个本地大语言模型(LLM),例如 DeepSeek-R1:
ollama pull deepseek-r1:8b(三)克隆项目仓库
通过 Git 命令克隆 Ollama Deep Researcher 的 GitHub 仓库到本地:
git clone https://github.com/langchain-ai/ollama-deep-researcher.git
cd ollama-deep-researcher(四)配置环境变量
根据您的需求,配置以下环境变量:
– `OLLAMA_BASE_URL`:Ollama 服务的端点,默认为 `http://localhost:11434`。
– `OLLAMA_MODEL`:使用的模型,默认为 `llama3.2`。
– `SEARCH_API`:使用的搜索引擎,可选值为 `duckduckgo`(默认)、`tavily` 或 `perplexity`。如果使用 `tavily` 或 `perplexity`,需要设置对应的 API 密钥。
– `TAVILY_API_KEY`:如果使用 Tavily 搜索引擎,需要设置此 API 密钥。
– `PERPLEXITY_API_KEY`:如果使用 Perplexity 搜索引擎,需要设置此 API 密钥。
– `MAX_WEB_RESEARCH_LOOPS`:最大研究循环次数,默认为 `3`。
– `FETCH_FULL_PAGE`:如果使用 `duckduckgo` 搜索 API,设置为 `true` 可获取完整页面内容,默认为 `false`。
例如,使用 DuckDuckGo 搜索引擎并设置最大循环次数为 3 的配置命令如下:
export SEARCH_API=duckduckgo
export MAX_WEB_RESEARCH_LOOPS=3(五)创建虚拟环境(推荐)
创建并激活虚拟环境:
python -m venv .venv
source .venv/bin/activate # Linux/Mac
.venv\Scripts\Activate.ps1 # Windows(六)安装依赖并启动 LangGraph 服务器
安装依赖并启动 LangGraph 服务器:
# 安装 uv 包管理器(仅在 Linux/Mac 下需要)
curl -LsSf https://astral.sh/uv/install.sh | sh
# 安装依赖
pip install -r requirements.txt
# 启动 LangGraph 服务器
uvx --refresh --from "langgraph-cli[inmem]" --with-editable . --python 3.11 langgraph dev(七)使用 LangGraph Studio UI
启动 LangGraph 服务器后,浏览器将自动打开 LangGraph Studio UI 页面。您可以通过以下步骤进行配置:
1. 在配置选项卡中,选择您希望使用的搜索引擎(默认为 DuckDuckGo)。
2. 设置您希望使用的本地 LLM 模型(默认为 llama3.2)。
3. 设置研究迭代深度(默认为 3)。
输入研究主题后,即可开始研究过程,并通过可视化界面查看研究进度。
六、结语
Ollama Deep Researcher 作为一款功能强大的本地化 AI 研究助手,凭借其自动迭代搜索、本地化运行保障数据隐私、灵活的配置选项以及自动生成研究报告等优势,在科研、商业和技术等多个领域展现出了巨大的应用潜力。它不仅能够帮助用户节省大量时间和精力,提高研究效率,还能为用户带来更深入、更全面的研究成果。
七、项目资料
- GitHub 项目地址:https://github.com/langchain-ai/ollama-deep-researcher
- Ollama 官网:https://ollama.com
- DeepSeek-R1 模型介绍:https://ollama.com/library/deepseek-r1
转载作品,原作者:小兵的AI视界,文章来源:https://mp.weixin.qq.com/s/Ct7_10q7FJe6lMUBlH7bgw
 微信赞赏
微信赞赏  支付宝赞赏
支付宝赞赏 
