


项目介绍
GPT-SoVITS 是一款强大的支持少量语音转换、文本到语音的音色克隆模型。支持中文、英文、日文的语音推理。
据开发者及各大博主测验,仅需提供 5 秒语音样本即可体验达到 80%~95% 像的声音克隆。若提供 1 分钟语音样本可以逼近真人的效果,且训练出高质量的 TTS 模型!
项目地址:
https://github.com/RVC-Boss/GPT-SoVITS
目前已获得 5.1k Star,看到很多人对其评价为目前最强中文语音克隆工具。
特征:
▪ 零样本 TTS:输入 5 秒语音样本并体验即时文本到语音转换。
▪ Few-shot TTS:仅用 1 分钟的训练数据即可微调模型,以提高语音相似度和真实感。
▪ 跨语言支持:用与训练数据集不同的语言进行推理,目前支持英语、日语和中文。
▪ WebUI工具:集成工具包括语音伴奏分离、自动训练集分割、中文ASR和文本标注,帮助初学者创建训练数据集和GPT/SoVITS模型。
使用方式
如果是 Windows 可直接开箱使用。
只需下载项目中的 prezip,解压并双击 go-webui.bat文件 即可启动 GPT-SoVITS-WebUI,然后通过界面方式操作即可。
项目环境依赖:
GPT-SoVITS 依赖于开源音视频全能转码工具 FFmpeg。这个需要我们根据不同的系统进行手动安装。
conda 环境安装:
conda install ffmpegUbuntu/Debian 用户:
sudo apt install ffmpeg
sudo apt install libsox-dev
conda install -c conda-forge 'ffmpeg<7'Mac 操作系统用户:
brew install ffmpegWindows操作系统用户:
需手动下载ffmpeg.exe和ffprobe.exe并将其放置在 GPT-SoVITS 根目录下。
ffmpeg.exe下载地址:
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe
ffprobe.exe下载地址:
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe
预训练模型下载放置位置:

具体使用步骤:
1、打开项目根目录,将预置克隆音频放置根目录,然后双击go-webui.bat 运行项目。(可以发现它实际上执行了Python脚本webui.py)

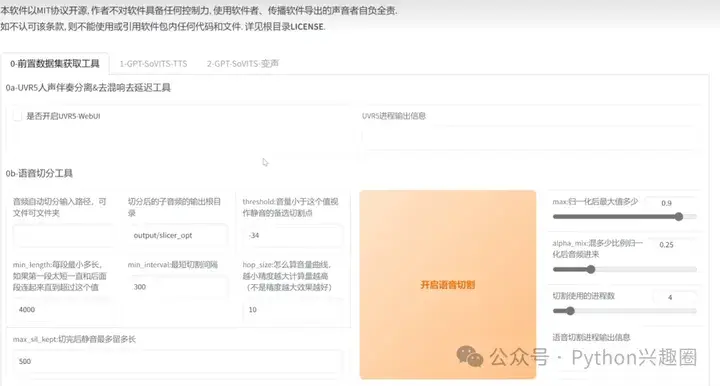
2、语音切割演示,将音频文件路径填入“音频自动切分输入路径”下,点击“开启语音切割”
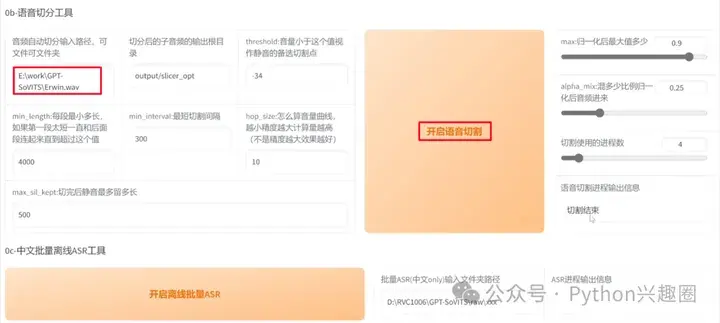
最终的切分结果会存放在项目Output下的slicer_opt目录下(切分成了20份)
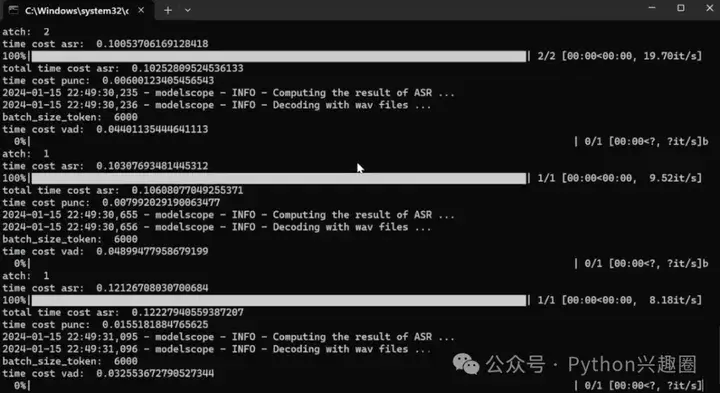
3、开始转写,将切分路径填入“中文批量离线ASR工具”输入路径下,转写结果文件会在Output下的asr_opt目录下生成


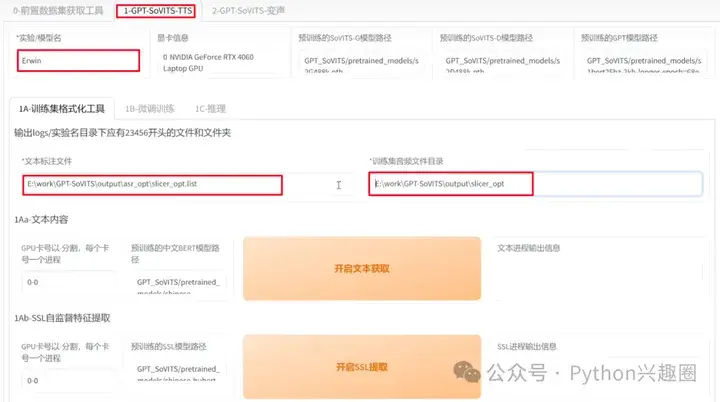
4、切换到GPT-SoVITS-TTS标签,填写模型名称(角色名),再分别填入之前生成的切分目录和转写目录路径,开启文本获取-开启SSL提取-语义Token提取(这3个步骤,一步一步来,一个完成之后再点击下一个),最后开启一键三连
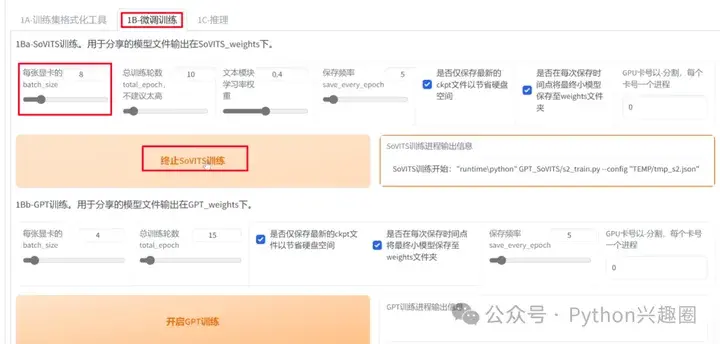
然后转到“微调训练”,设置适合自己显卡的显存,“开启SoVits训练”,然后SoVits训练结束后,再“开启GPT训练”
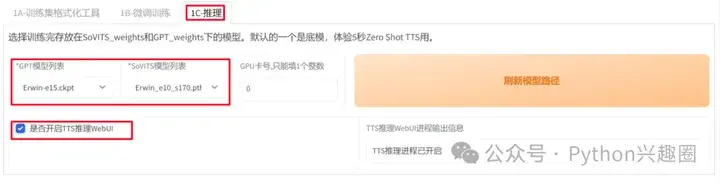
5、选择“推理”标签栏,设置GPT和SoVits的模型,勾选“是否开启TTS推理WebUI”,等一会回自动跳转到一个新的“推理界面”
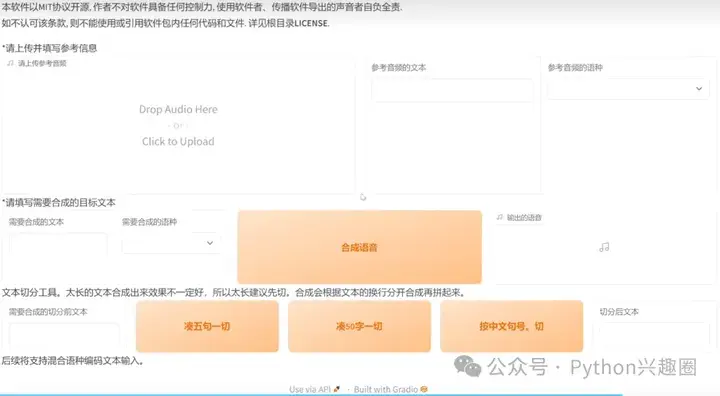
6、填写参考音频信息(音频文件、音频文本、语种)、合成音频信息(音频文本,语音),点击合成语音,最后就完成了语音转换。
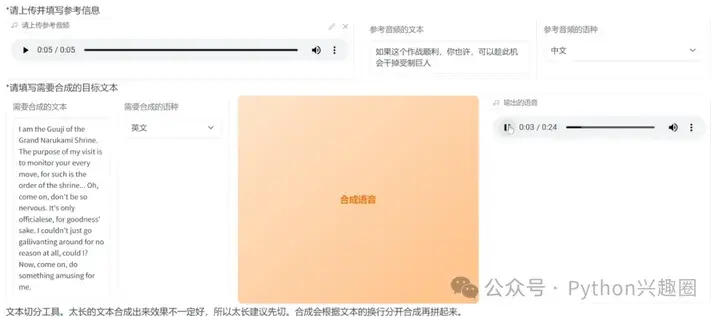
GPT-SoVITS 支持跨语言,集成了声音伴奏分离、自动训练集分割、中文ASR和文本标注等辅助工具。
转载作品,原作者:,文章来源:https://www.toutiao.com/article/7328045075459113508
 微信赞赏
微信赞赏  支付宝赞赏
支付宝赞赏 
